
Lecciones de la desastrosa presentación de GPT-5
OpenAI presentó GPT-5 esta semana entre fuertes críticas de sus usuarios. Analizamos el lanzamiento, qué salió mal, y cómo podemos evitar caer presa de los mismos errores en nuestros productos.

OpenAI ha tenido una mala semana. El anticipado advenimiento de GPT-5, del que muchos esperaban fuera un salto decidido hacia a AGI, ha resultado ser un tremendo desencanto. Para muestra, el día después al lanzamiento, este fue el post más votado en el subreddit de OpenAI:
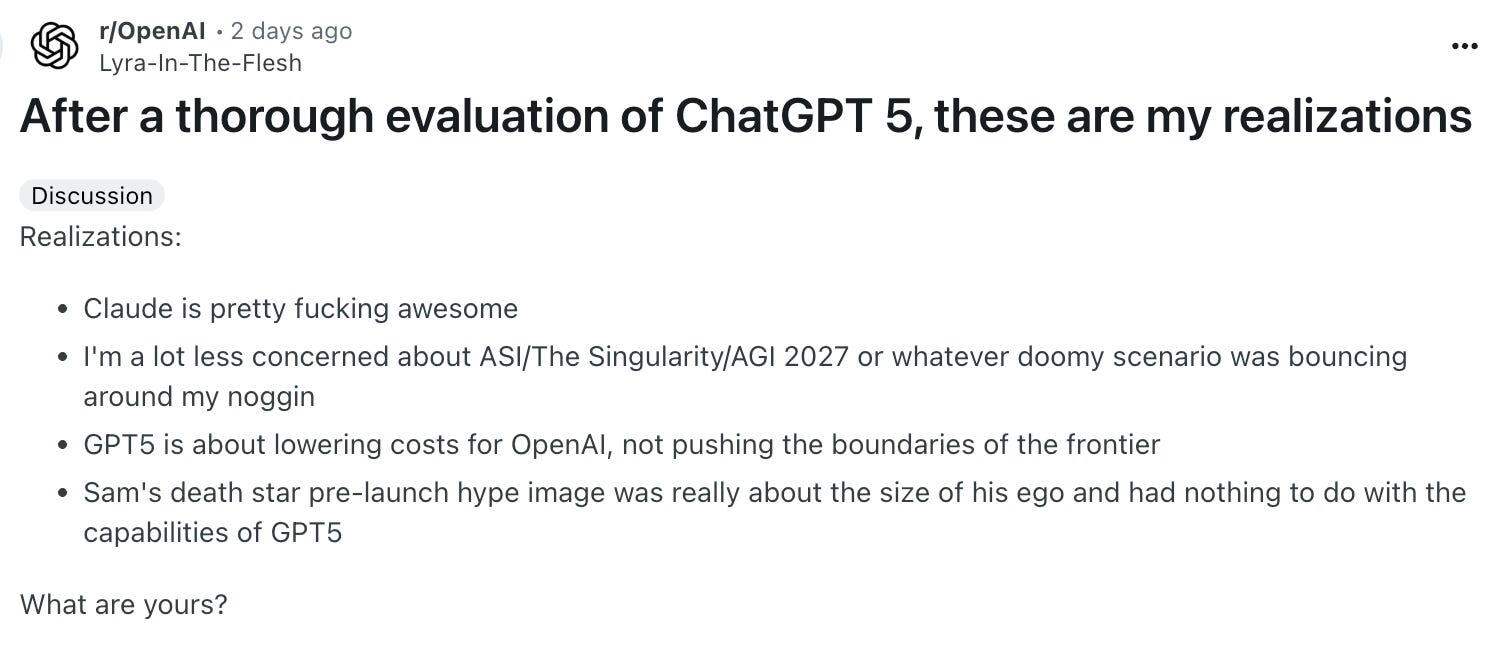
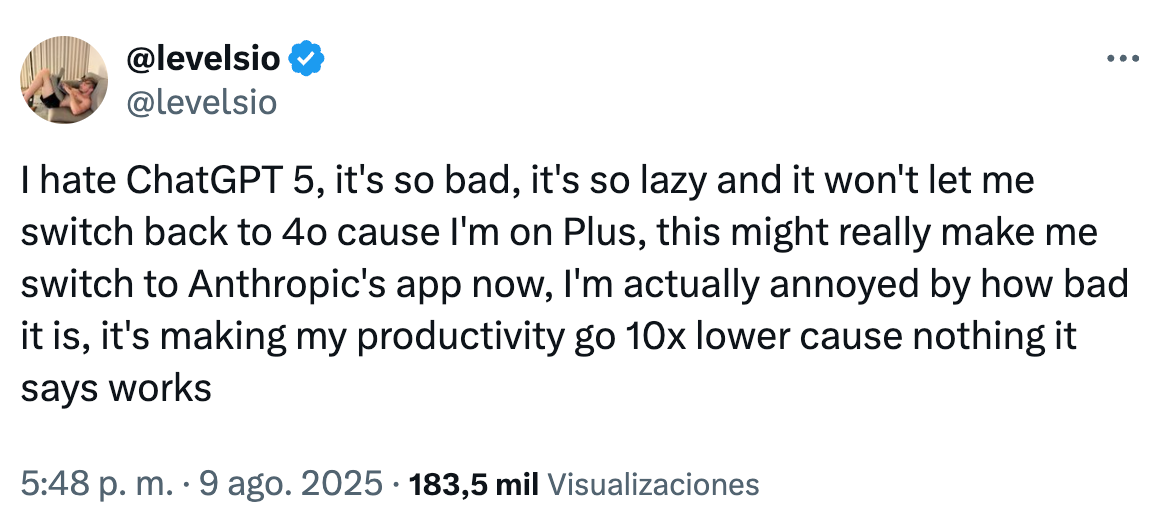
La recepción en X ha sido igualmente crítica. Pieter Levels, probablemente el Indie Hacker más famoso de Internet, y un gran promotor de la IA, comentaba sobre GPT-5:
El objetivo del artículo de hoy es analizar el lanzamiento de GPT-5 para no repetirlo. Dividiremos el artículo en cuatro actos:
En el primero, analizaremos lo que dijo OpenAI en su presentación.
En el segundo, lo que dicen sus usuarios y clientes.
En el tercero veremos qué dicen los datos.
Y por último, analizaremos qué ha salido mal y qué podría haber hecho OpenAI para evitar el desastre.
Lo que OpenAI dijo
OpenAI, como anticipando algo, hizo una presentación de GPT-5 bastante soporífera, llegando a mostrar alguna gráfica que daría rubor a Jack Sparrow en el cenit de su carrera pirata.
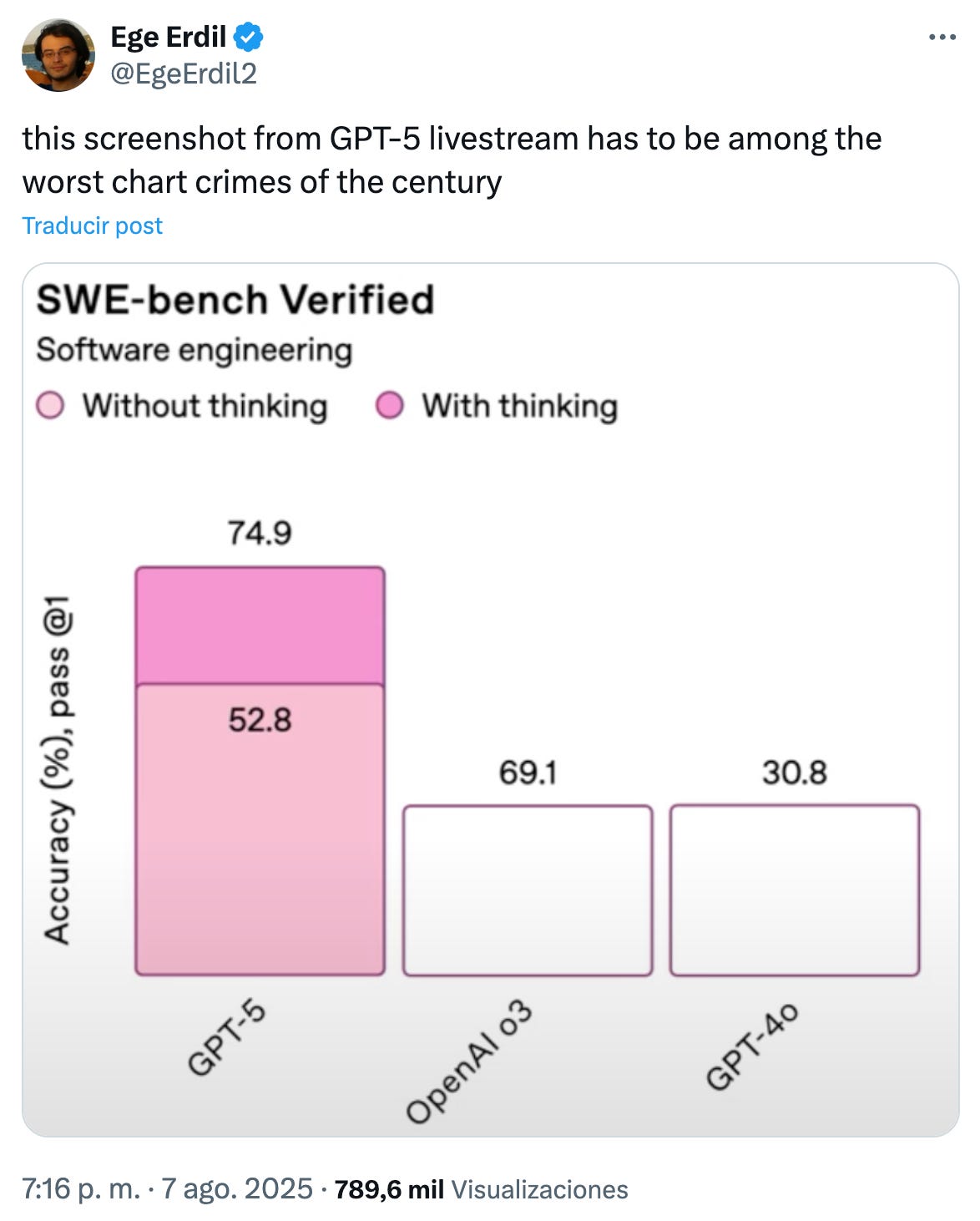
A modo de resumen, estos fueron los aspectos que OpenAI destacó:
Sistema unificado: GPT-5 utiliza un enrutador inteligente para decidir entre respuestas rápidas y razonamientos más profundos, adaptándose a la complejidad de cada consulta.
Rendimiento: Destaca en programación (especialmente en desarrollo front-end complejo y depuración), escritura creativa y asesoramiento en salud, con mejoras significativas en precisión, seguimiento de instrucciones y reducción de alucinaciones.
Pruebas de referencia (benchmarks): GPT-5 establece nuevos resultados de vanguardia en matemáticas, programación, comprensión multimodal y salud, superando a modelos anteriores en las principales pruebas académicas y del mundo real.
Fiabilidad y seguridad: El modelo es menos propenso a alucinar o dar respuestas engañosas, comunica mejor sus limitaciones y cuenta con un entrenamiento de seguridad avanzado para ofrecer respuestas útiles, honestas y matizadas.
Personalización: Los usuarios pueden elegir entre nuevas personalidades predefinidas (Cínico, Robot, Oyente, Friki) para diferentes estilos de interacción.
Acceso: GPT-5 es el nuevo modelo por defecto en GPT, con acceso ilimitado para usuarios Pro y una versión especial “GPT-5 Pro” para las tareas más complejas. Los usuarios gratuitos tienen acceso con ciertos límites de uso.
Lo que dicen los usuarios
En principio, lo que dijo OpenAI sonaba bien. Pocos podrían estar en contra de simplificar la experiencia de uso de ChatGPT, obtener un mejor rendimiento o una reducción en la tasa de alucinaciones. Sin embargo, del dicho al hecho hay un trecho, y lo que los usuarios y clientes de OpenAI experimentaron fue bastante distinto de lo prometido.
Algunas de las principales quejas fueron:
Pérdida de acceso a modelos anteriores: El despliegue de GPT-5 vino con una sorpresa, y es que inicialmente, OpenAI retiró la posibilidad de escoger manualmente modelos anteriores. Esto ha generado múltiples críticas, especialmente de power users que ya tenían sus flujos de trabajo establecidos y preferían seleccionar ellos el modelo adecuado antes que confiar en el enrutado de GPT-5.
Límites de uso y de mensajes reducidos para usuarios Plus: Otra sorpresa fue que OpenAI ha añadido nuevos límites de uso sin que por ello hayan visto reducirse el precio de la suscripción. Por ejemplo, los usuarios Plus tienen ahora un límite de 160 mensajes cada 3h y 200 mensajes de razonamiento por semana.
Problemas de rendimiento: Las quejas incluyen tiempos de respuesta más lentos, respuestas breves o incompletas y errores ocasionales, incluidas alucinaciones o inexactitudes. Algunos usuarios afirman que GPT-5 es menos ágil o funcional para las tareas diarias en comparación con modelos anteriores.
Cambios en la personalidad y el tono: Muchos usuarios se quejan también de que GPT-5 carece de la calidez, la personalidad y la cercanía que apreciaban en GPT-4o, describiendo el nuevo modelo como más frío o “corporativo”, ofreciendo respuestas más breves y directas.
Respuestas erróneas: La opinión generalizada es que GPT-5 no es un salto a nivel de inteligencia. Sigue generando respuestas erróneas, y el aumento de la brevedad en las respuestas puede dificultar seguir su proceso de razonamiento.
Errores y problemas de estabilidad en el lanzamiento: Los usuarios reportaron fallos, errores y falta de consistencia en las primeras fases del despliegue, incluidos problemas con el sistema de enrutamiento que afectaban a la calidad de las respuestas.
Misma ventana de contexto: El cambio a GPT-5 no ha traído un aumento de tamaño en la ventana de contexto, que sigue siendo de escasos 32k. Esto contrasta con los 200k de Claude o el asombroso millón que ofrece Google con Gemini.
Entrenado con datos de 2024: Curiosamente, la fecha de corte de conocimiento de GPT-5, es el 1 de octubre de 2024. Esto es una mejora respecto 4o, que tenía su fecha de corte 2023, pero todavía inferior a la de Gemini 2.5 Pro, con fecha de corte de Enero de 2025, y presentado en Marzo de este año.
Lo que dicen los datos
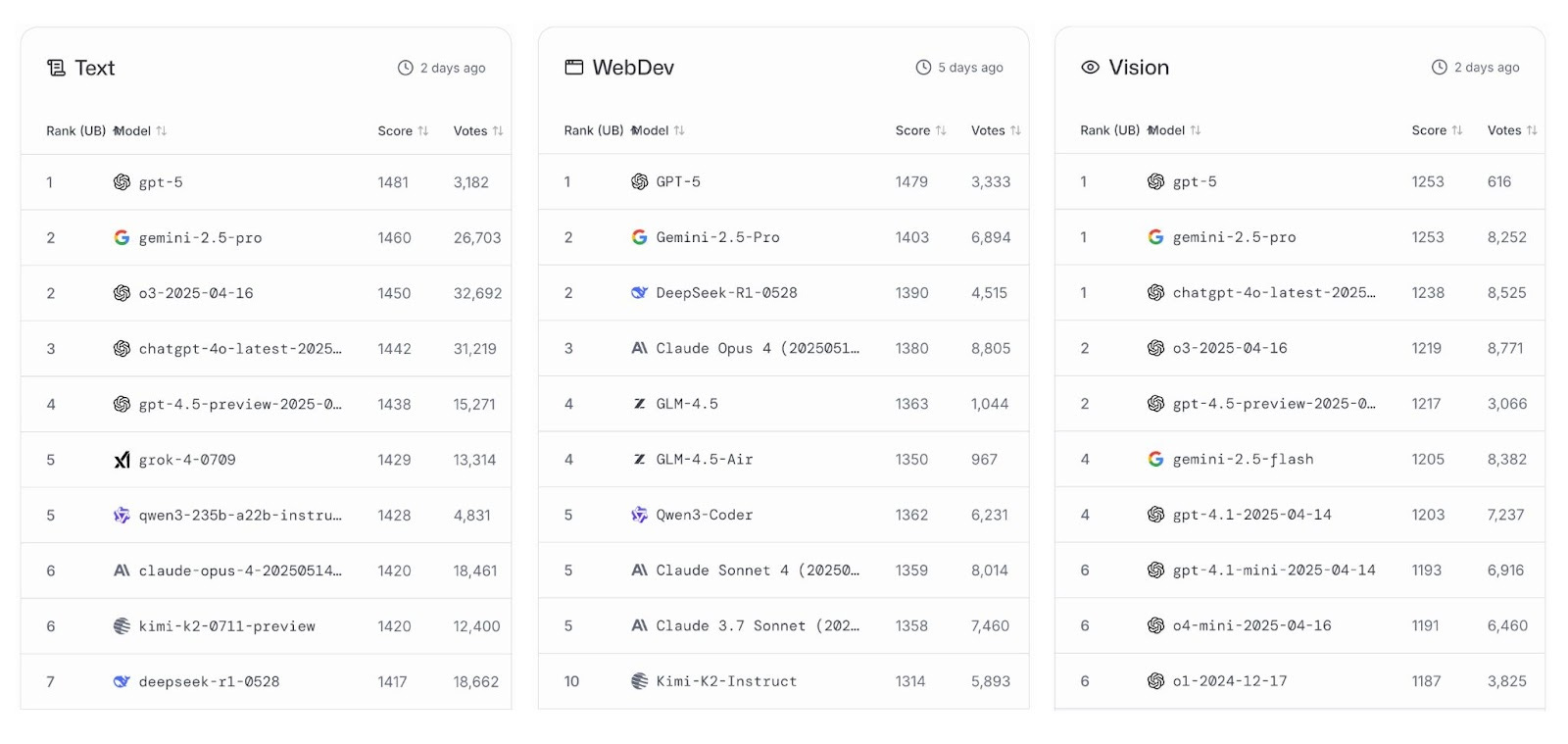
LMArena es una plataforma abierta creada por investigadores de Berkeley que permite evaluar modelos IA a través de votaciones de usuarios. Es considerado el sitio de referencia donde comparar modelos en distintas dimensiones.
A 9 de agosto de 2025, GPT-5 lidera las categorías de generación de texto, desarrollo web y visión. Observamos también resultados similares en otros similares, como LiveBench, Vellum, o ArtificialAnalysis.ai. Si bien su diferencia respecto a su más directo rival, Gemini 2.5 Pro, es bastante escasa, creo que podemos afirmar que GPT-5 parece un buen modelo.
Lo que pudo haber hecho OpenAI
Si GPT-5 es un buen modelo, ¿por qué la recepción del público ha sido tan desastrosa? Varios elementos han contribuido al ultraje, y de ellos podemos sacar valiosos aprendizajes.
En primer lugar, Sam Altman, CEO de OpenAI, creó un hype desmedido por GPT-5. Altman, poco antes del lanzamiento confesaba estar asustado de lo que iban a liberar, y el propio día del mismo, lanzó un post en X donde se veía a la Estrella de la Muerte aparecer sobre el horizonte.
Cuando el modelo cayó en manos de los usuarios, y estos comenzaron a ver que el salto en inteligencia era relativamente pequeño, la decepción fue total.
Una pregunta interesante es por qué Altman ha seguido hinchando el globo cuando a todas luces dentro de OpenAI debían saber que GPT-5 iba a ser una mejora incremental y no un salto revolucionario. ¿Está tan alejado de la realidad que pensaba que podría salirse con la suya? ¿O quizás está tan presionado por levantar financiación a valoraciones estratosféricas, que no le queda otra que tratar de vender lo que no tiene? No lo podemos saber, pero desde luego, la falta de credibilidad de Altman empieza a ser un problema para OpenAI.
El despliegue del modelo también fue complicado, con problemas precisamente en la capacidad estrella de GPT-5, el enrutamiento. Según las propias palabras de Altman:
GPT-5 will seem smarter starting today. Yesterday, the autoswitcher broke and was out of commission for a chunk of the day, and the result was GPT-5 seemed way dumber. Also, we are making some interventions to how the decision boundary works that should help you get the right model more often.
En el mismo post de X, Altman también recoge cable en dos de las principales quejas de los usuarios, los nuevos límites de uso y la posibilidad de seleccionar 4o en lugar de GPT-5:
We are going to double GPT-5 rate limits for ChatGPT Plus users as we finish rollout.
We will let Plus users choose to continue to use 4o. We will watch usage as we think about how long to offer legacy models for.
La falta de transparencia y anticipación de los cambios, ha sido sin duda uno de los problemas fundamentales del lanzamiento. Cuando has educado a millones de power users a seleccionar modelos y crear flujos de trabajo alrededor de los mismos, no puedes sacarlos de circulación de un plumazo de un día para otro.
En definitiva, muchos errores autoinfligidos que han ensombrecido lo que debería haber sido un lanzamiento a todo lo grande de OpenAI. Ahora bien, ¿qué lecciones podemos extraer del fiasco del lanzamiento de GPT-5?
La gente es siempre reacia a los cambios. Si vas a introducir modificaciones fundamentales en su experiencia con una actualización, prepárate de una o varias de estas formas:
Anticipa claramente los cambios para que a nadie le pillen por sorpresa.
No hagas desaparecer las versiones anteriores de forma que los más atados a ellas puedan seguir usándolas.
Si de verdad estás convencido de que los cambios son a mejor y/o necesarios, prepara una buena defensa de los mismos de antemano. Prepara también a los equipos de soporte y redes para que estén listos para soportar el rechazo inicial. Si los cambios resultan ser realmente buenos, el ruido pasará.
No sobreprometas. Siempre es mejor sorprender a tus usuarios que defraudarles. Es más fácil sorprender cuando llevas un perfil bajo, que cuando te pasas meses diciendo que estás tocando la AGI con las manos y luego presentas una castaña.
Testea con grupos de usuarios diversos. Unos cuántos tests con usuarios plus habrían revelado muchos de los problemas que a OpenAI le explotaron en la cara el día del lanzamiento.
Asegúrate de que el despliegue funcione correctamente. Que el primer día se rompa el enrutador haciendo que tu modelo parezca menos listo de lo que es, no genera demasiada confianza. Es mejor asegurar un despliegue lento, pero seguro, que exponerte a quedar en evidencia.
Concluyendo, el muy mejorable lanzamiento de GPT-5 ilustra como mejoras técnicas aparentemente legítimas pueden ser eclipsadas por errores de comunicación y ejecución.
En mercados maduros, con usuarios sofisticados, cómo comunicar y ejecutar un cambio es tan importante como la propia mejora que estás introduciendo.
Buenos días Simón,
buen resumen.
Un detalle, creo que está parte no es del todo precisa:
Misma ventana de contexto: El cambio a GPT-5 no ha traído un aumento de tamaño en la ventana de contexto, que sigue siendo de escasos 32k. Esto contrasta con los 200k de Claude o el asombroso millón que ofrece Google con Gemini.
La ventana de contexto ha aumentado con respecto a 4o (ahora son 400k tokens) pero no con respecto a 4.1 (que eran 1M igual que Gemini). En cualquier caso aparte del número quizá lo más importante es como de bien los modelos pueden utilizar el contexto.
Un saludo y gracias por compartir este resumen de las lecciones.
Llevo más de un año trabajando con ChatGPT y tenía perfiles y flujos de trabajo muy bien definidos que funcionaban a la perfección.
Con los cambios recientes, todo se ha modificado… y no precisamente para mejor. Flujos que antes eran fiables ya no responden como esperaba, y la calidad que conocía ha bajado.
Que lastima llegar a esto...